

みなさま、普段の生活や業務の中で「ID」という言葉を目にすることは多いかと思います。
例えばオンラインサービスを利用する際、ログインIDとパスワードの登録を求められるのが一般的です。
パスワードがセキュリティ保護のために重要であることは言うまでもありませんが、では「ID」の役割や意義とは一体何なのでしょうか。当たり前のように設定してきましたが、改めてその本質を考える機会は少ないかもしれません。
IDとは、英語の「Identifier(識別子)」や「Identification(身分証明・同定)」の略称であり、一言で言えば「個別の要素を識別するための情報」という意味を持ちます。
「ログインID」を例に挙げると、その役割は「世界中に存在する不特定多数のアカウントの中から、特定のユーザーを唯一無二の存在として識別する」ことにあります。仮にパスワードのみで認証を行う仕組みだったとしたら、数文字程度の文字列では他者と重複してしまい、誰のアカウントなのか判別できなくなるトラブルが容易に想像できます。
この「ID(識別子)」という概念は、実は日々の業務効率化においても非常に重要な役割を果たします。その代表的な活用例が、Excelの「VLOOKUP関数」です。
VLOOKUP関数は、特定の値をキーにして表からデータを検索し、対応する値を抽出してくれる便利な関数ですが、ここで「各データに一意のIDを振る」という作業が極めて重要になります。なぜなら、データ内に同姓同名や同じ名称の項目が重複していても、IDさえあればシステムが混同することはないからです。
具体的な例を見てみましょう。以下のような「果物名・産地・単価」をまとめた緑色のリストがあるとします。
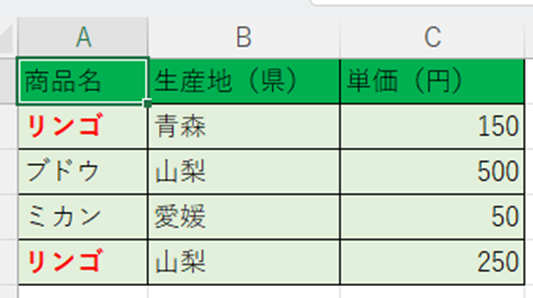
この緑色のリストでは「リンゴ」が重複していますが、産地や単価が異なります。ここで「果物名」を検索条件にしてVLOOKUP関数でデータを呼び出そうとすると(下記黄色リストの通り)、
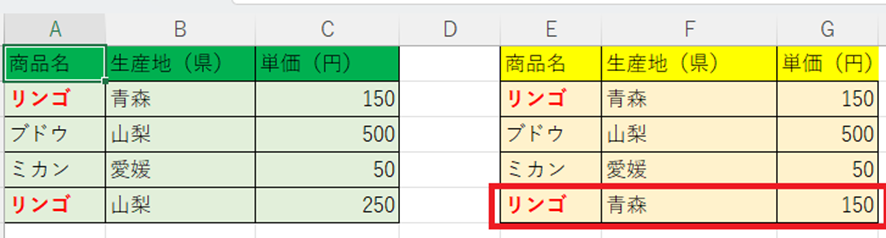
関数は通常「最初に見つけたデータ」を優先するため、下段にある「山梨県産」のデータが正しく取得できないという問題が発生します。
しかし、各項目に「0001」「0002」といった固有のIDを振り、そのIDを基準にVLOOKUP関数を使用してみるとどうでしょうか。
たとえ果物名が同じ「リンゴ」であっても、(下記青色リストの通り)IDが異なれば、Excelはそれぞれを別個のデータとして正しく識別し、正確な値を抽出してくれます。
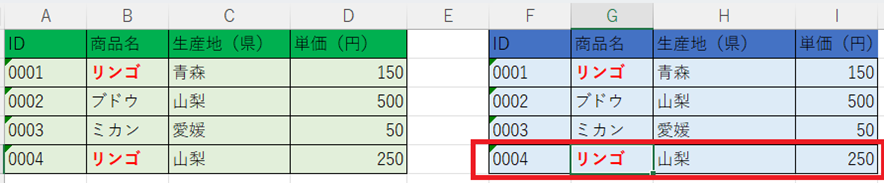
このように、項目を「識別」するためにIDを振ることは、データの整合性を守るための大原則です。冒頭で触れた「ログインID」も、このVLOOKUPの例も、根底にある考え方は同じなのです。
VLOOKUP関数の活用を通して、改めてID(識別子)の大切さに気づかされたというお話でした。 (年始早々、少し理屈っぽいお話になってしまいましたが、本年もどうぞよろしくお願いいたします。)